Python For Data Analysis-八章第一节
《Python For Data Analysis》的第八章主要讨论的是数据的组合、合并和变形等问题。
17.1 层次化索引
层次化索引(hierarchical indexing)是pandas的一项重要功能, 有点像表格的合并单元格,它使你能在一个轴上拥有多个(两个以上)索引级别。有了层次化索引之后,可以很容易的访问分块数据以及做一些基于组的操作(group-based),比如做一个数据透视表(pivot table)。
以某学生的课表为例,可以很好的解释层次化索引结构的作用。
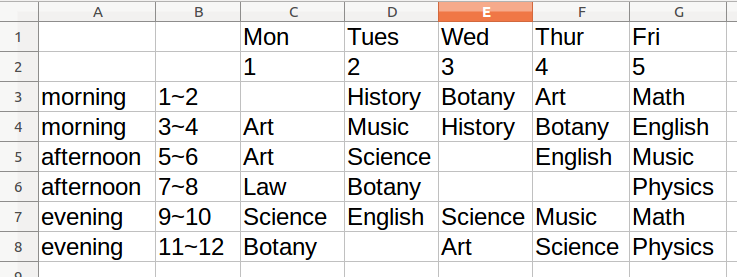
上图是下面的程序最后导出的csv文件用excel类软件打开的结果。这是一张课程表timetable,有上午、下午和晚上的各个课程信息,完全由程序生成。程序代码如下所示:
import pandas as pd
import numpy as np
print "-" * 40
course_name = ["Math", "English","Music", "Physics", "History",
"Law", "Botany", "Science", "Art", ""]
print course_name, "# course_name"
print "-" * 40
course_number = range(len(course_name))
print course_number, "# course_number"
print "-" * 40
d_map = dict(zip(course_number, course_name))
print d_map, "# dict for map"
# random number for timetable
print "-" * 40
dd = np.random.randint(0,len(course_name), size = 30).reshape((6,5))
df = pd.DataFrame(dd,
index=[['morning', 'morning', 'afternoon', 'afternoon', 'evening', 'evening'],
["1~2", "3~4", "5~6", "7~8", "9~10", "11~12"]],
columns=[["Mon", "Tues", "Wed", "Thur", "Fri"],
[1, 2, 3, 4, 5]])
print df, "# df random timetable in number"
print "-" * 40
for i in df.columns:
df.update(df[i].map(d_map))
print df, "# df timetable in names"
print "-" * 40
print df.loc["morning", "3~4"]
print "-" * 40
df.to_csv("time.csv")
执行结果:
----------------------------------------
['Math', 'English', 'Music', 'Physics', 'History', 'Law', 'Botany', 'Science', 'Art', ''] # course_name
----------------------------------------
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # course_number
----------------------------------------
{0: 'Math', 1: 'English', 2: 'Music', 3: 'Physics', 4: 'History', 5: 'Law', 6: 'Botany', 7: 'Science', 8: 'Art', 9: ''} # dict for map
----------------------------------------
Mon Tues Wed Thur Fri
1 2 3 4 5
morning 1~2 9 4 6 8 0
3~4 8 2 4 6 1
afternoon 5~6 8 7 9 1 2
7~8 5 6 9 9 3
evening 9~10 7 1 7 2 0
11~12 6 9 8 7 3 # df random timetable in number
----------------------------------------
Mon Tues Wed Thur Fri
1 2 3 4 5
morning 1~2 History Botany Art Math
3~4 Art Music History Botany English
afternoon 5~6 Art Science English Music
7~8 Law Botany Physics
evening 9~10 Science English Science Music Math
11~12 Botany Art Science Physics # df timetable in names
----------------------------------------
Mon 1 Art
Tues 2 Music
Wed 3 History
Thur 4 Botany
Fri 5 English
Name: (morning, 3~4), dtype: object
----------------------------------------
来解释一下程序的各个部分:
1). 首先是列出所有课程信息,这里用course_name来记录所有的课程的名字。
course_name = ["Math", "English","Music", "Physics", "History",
"Law", "Botany", "Science", "Art", ""]
2). 课程编号
course_number = range(len(course_name))
设置课程编号的目的是后续随机构建一个5天6节课的课表,先用数字来填充每节课,之后借助字典
d_map = dict(zip(course_number, course_name))
使用map函数将课程编号换成对应的课程名字。
3). 生成随机课表二维矩阵。
dd = np.random.randint(0,len(course_name), size = 30).reshape((6,5))
语句reshape((6,5)是5天,每天6节课。
4). 构建多层次索引的dataframe数据df。
df = pd.DataFrame(dd,
index=[['morning', 'morning', 'afternoon', 'afternoon', 'evening', 'evening'],
["1~2", "3~4", "5~6", "7~8", "9~10", "11~12"]],
columns=[["Mon", "Tues", "Wed", "Thur", "Fri"],
[1, 2, 3, 4, 5]])
5). 借助map函数将每列的课程编号换成课程名字。
for i in df.columns:
df.update(df[i].map(d_map))
6). 打印上午三四节的课程信息。
print df.loc["morning", "3~4"]
7). 最后将df数据输出到.csv文件,
df.to_csv("time.csv")
这里需要注意的是
print "-" * 40
for i in df.columns:
df.update(df[i].map(d_map))
print df, "# df timetable in names"
print "-" * 40
的打印结果
----------------------------------------
Mon Tues Wed Thur Fri
1 2 3 4 5
morning 1~2 History Botany Art Math
3~4 Art Music History Botany English
afternoon 5~6 Art Science English Music
7~8 Law Botany Physics
evening 9~10 Science English Science Music Math
11~12 Botany Art Science Physics # df timetable in names
----------------------------------------
和上图不一致,这是pandas输出处理了一下,从图可看出,其实每行都有两个索引,为了美观第一个行索引没有每行都打印出来。
- 层次化索引的dataframe可以为其index和column均设置名字name。
import pandas as pd
import numpy as np
print "-" * 40
course_name = ["Math", "English","Music", "Physics", "History",
"Law", "Botany", "Science", "Art", ""]
print course_name, "# course_name"
print "-" * 40
course_number = range(len(course_name))
print course_number, "# course_number"
print "-" * 40
d_map = dict(zip(course_number, course_name))
print d_map, "# dict for map"
# random number for timetable
print "-" * 40
dd = np.random.randint(0,len(course_name), size = 30).reshape((6,5))
df = pd.DataFrame(dd,
index=[['morning', 'morning', 'afternoon', 'afternoon', 'evening', 'evening'],
["1~2", "3~4", "5~6", "7~8", "9~10", "11~12"]],
columns=[["Mon", "Tues", "Wed", "Thur", "Fri"],
[1, 2, 3, 4, 5]])
print df, "# df random timetable in number"
print "-" * 40
for i in df.columns:
df.update(df[i].map(d_map))
print df, "# df timetable in names"
df.index.names = ["part", "section"]
df.columns.names = ["week", "day"]
print "-" * 40
print df, "# df with names"
print "-" * 40
由于是随机生成的课程矩阵,所以结果有不一致:
----------------------------------------
['Math', 'English', 'Music', 'Physics', 'History', 'Law', 'Botany', 'Science', 'Art', ''] # course_name
----------------------------------------
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # course_number
----------------------------------------
{0: 'Math', 1: 'English', 2: 'Music', 3: 'Physics', 4: 'History', 5: 'Law', 6: 'Botany', 7: 'Science', 8: 'Art', 9: ''} # dict for map
----------------------------------------
Mon Tues Wed Thur Fri
1 2 3 4 5
morning 1~2 3 4 5 9 1
3~4 3 2 1 6 2
afternoon 5~6 0 1 8 6 8
7~8 2 0 6 5 6
evening 9~10 9 5 4 8 7
11~12 9 5 0 6 7 # df random timetable in number
----------------------------------------
Mon Tues Wed Thur Fri
1 2 3 4 5
morning 1~2 Physics History Law English
3~4 Physics Music English Botany Music
afternoon 5~6 Math English Art Botany Art
7~8 Music Math Botany Law Botany
evening 9~10 Law History Art Science
11~12 Law Math Botany Science # df timetable in names
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 2 3 4 5
part section
morning 1~2 Physics History Law English
3~4 Physics Music English Botany Music
afternoon 5~6 Math English Art Botany Art
7~8 Music Math Botany Law Botany
evening 9~10 Law History Art Science
11~12 Law Math Botany Science # df with names
----------------------------------------
语句
df.index.names = ["part", "section"]
df.columns.names = ["week", "day"]
可以给index和columns设置名字,便于后续函数使用。
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 2 3 4 5
part section
morning 1~2 Physics History Law English
3~4 Physics Music English Botany Music
afternoon 5~6 Math English Art Botany Art
7~8 Music Math Botany Law Botany
evening 9~10 Law History Art Science
11~12 Law Math Botany Science # df with names
----------------------------------------
17.2 调整索引级别
pandas 的swaplevel函数可以调整层次化索引的级别。
import pandas as pd
import numpy as np
course_name = ["Math", "English","Music", "Physics", "History",
"Law", "Botany", "Science", "Art", ""]
course_number = range(len(course_name))
d_map = dict(zip(course_number, course_name))
dd = np.random.randint(0,len(course_name), size = 30).reshape((6,5))
df = pd.DataFrame(dd,
index=[['morning', 'morning', 'afternoon', 'afternoon', 'evening', 'evening'],
["1~2", "3~4", "5~6", "7~8", "9~10", "11~12"]],
columns=[["Mon", "Tues", "Wed", "Thur", "Fri"],
[1, 2, 3, 4, 5]])
for i in df.columns:
df.update(df[i].map(d_map))
df.index.names = ["part", "section"]
df.columns.names = ["week", "day"]
print "-" * 40
print df, "# df with names"
print "-" * 40
print df.swaplevel("part", "section"), "# swaplevel"
print "-" * 40
执行结果:
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 2 3 4 5
part section
morning 1~2 Music Art Physics Art Math
3~4 History Physics Art Art Physics
afternoon 5~6 History Math Science Math Botany
7~8 Art Botany Music Music Math
evening 9~10 Music Botany Law English
11~12 Art History History Botany Music # df with names
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 2 3 4 5
section part
1~2 morning Music Art Physics Art Math
3~4 morning History Physics Art Art Physics
5~6 afternoon History Math Science Math Botany
7~8 afternoon Art Botany Music Music Math
9~10 evening Music Botany Law English
11~12 evening Art History History Botany Music # swaplevel
----------------------------------------
17.3 索引分级重排数据
由于层次化索引,以行为例,数据按行号排序sort_index是用最外层的还是最内层作为排序标准?可以选择不同的级别来进行数据排序,可以通过level来指定,最外层的行索引为0。
import pandas as pd
import numpy as np
course_name = ["Math", "English","Music", "Physics", "History",
"Law", "Botany", "Science", "Art", ""]
course_number = range(len(course_name))
d_map = dict(zip(course_number, course_name))
dd = np.random.randint(0,len(course_name), size = 30).reshape((6,5))
df = pd.DataFrame(dd,
index=[['morning', 'morning', 'afternoon', 'afternoon', 'evening', 'evening'],
["1~2", "3~4", "5~6", "7~8", "9~10", "11~12"]],
columns=[["Mon", "Tues", "Wed", "Thur", "Fri"],
[1, 2, 3, 4, 5]])
for i in df.columns:
df.update(df[i].map(d_map))
df.index.names = ["part", "section"]
df.columns.names = ["week", "day"]
print "-" * 40
print df, "# df with names"
print "-" * 40
print df.sort_index(level = 0), "# level = 0"
print "-" * 40
print df.sort_index(level = 1), "# level = 1"
print "-" * 40
执行结果:
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 2 3 4 5
part section
morning 1~2 History Math Math Law Art
3~4 Botany Art Math Music History
afternoon 5~6 English Art History English Physics
7~8 Music Law Art Physics Music
evening 9~10 History Art Physics History
11~12 History Science Law Law # df with names
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 2 3 4 5
part section
afternoon 5~6 English Art History English Physics
7~8 Music Law Art Physics Music
evening 11~12 History Science Law Law
9~10 History Art Physics History
morning 1~2 History Math Math Law Art
3~4 Botany Art Math Music History # level = 0
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 2 3 4 5
part section
evening 11~12 History Science Law Law
morning 1~2 History Math Math Law Art
3~4 Botany Art Math Music History
afternoon 5~6 English Art History English Physics
7~8 Music Law Art Physics Music
evening 9~10 History Art Physics History # level = 1
----------------------------------------
level=0意思是按"part"下的值来排序数据,level=1意思是按"section"下的值来排序数据。
* sort_index函数默认(axis=0)是行排序,也可列排序(axis=1)。
import pandas as pd
import numpy as np
course_name = ["Math", "English","Music", "Physics", "History",
"Law", "Botany", "Science", "Art", ""]
course_number = range(len(course_name))
d_map = dict(zip(course_number, course_name))
dd = np.random.randint(0,len(course_name), size = 30).reshape((6,5))
df = pd.DataFrame(dd,
index=[['morning', 'morning', 'afternoon', 'afternoon', 'evening', 'evening'],
["1~2", "3~4", "5~6", "7~8", "9~10", "11~12"]],
columns=[["Mon", "Tues", "Wed", "Thur", "Fri"],
[1, 2, 3, 4, 5]])
for i in df.columns:
df.update(df[i].map(d_map))
df.index.names = ["part", "section"]
df.columns.names = ["week", "day"]
print "-" * 40
print df, "# df with names"
print "-" * 40
print df.sort_index(axis = 0), "# axis = 0"
print "-" * 40
print df.sort_index(axis = 1), "# axis = 1"
print "-" * 40
print df.sort_index(axis = 1, level = 1,ascending=False), "# axis = 1"
print "-" * 40
执行结果:
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 2 3 4 5
part section
morning 1~2 Science History Art Music Math
3~4 Science Math History Music
afternoon 5~6 English Art English Music Law
7~8 History Botany Music Science Music
evening 9~10 English Science Math Physics History
11~12 Physics Music Music Music English # df with names
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 2 3 4 5
part section
afternoon 5~6 English Art English Music Law
7~8 History Botany Music Science Music
evening 11~12 Physics Music Music Music English
9~10 English Science Math Physics History
morning 1~2 Science History Art Music Math
3~4 Science Math History Music # axis = 0
----------------------------------------
week Fri Mon Thur Tues Wed
day 5 1 4 2 3
part section
morning 1~2 Math Science Music History Art
3~4 Music Science History Math
afternoon 5~6 Law English Music Art English
7~8 Music History Science Botany Music
evening 9~10 History English Physics Science Math
11~12 English Physics Music Music Music # axis = 1
----------------------------------------
week Fri Thur Wed Tues Mon
day 5 4 3 2 1
part section
morning 1~2 Math Music Art History Science
3~4 Music History Math Science
afternoon 5~6 Law Music English Art English
7~8 Music Science Music Botany History
evening 9~10 History Physics Math Science English
11~12 English Music Music Music Physics # axis = 1, level = 1
----------------------------------------
17.4 层次化索引的分级统计
由于数据的索引层次化了,在对数据进行统计的时候,例如求和,也可以通过level参数来选择依据内层索引还是外层索引来统计结果。
import pandas as pd
import numpy as np
course_name = ["Math", "English","Music", "Physics", "History",
"Law", "Botany", "Science", "Art", ""]
course_number = range(len(course_name))
d_map = dict(zip(course_number, course_name))
dd = np.random.randint(0,len(course_name), size = 30).reshape((6,5))
df = pd.DataFrame(dd,
index=[['morning', 'morning', 'afternoon', 'afternoon', 'evening', 'evening'],
["1~2", "3~4", "5~6", "7~8", "9~10", "11~12"]],
columns=[["Mon", "Tues", "Wed", "Thur", "Fri"],
[1, 1, 2, 2, 3]])
print "-" * 40
print df
df.index.names = ["part", "section"]
df.columns.names = ["week", "day"]
print "-" * 40
print df.sum(level = 0), "# level = 0"
print "-" * 40
print df.sum(level = 1, axis = 1), "# level = 1, axis = 1"
print "-" * 40
执行结果:
----------------------------------------
Mon Tues Wed Thur Fri
1 1 2 2 3
morning 1~2 2 5 3 0 4
3~4 9 4 5 9 2
afternoon 5~6 8 9 3 4 9
7~8 3 7 3 8 1
evening 9~10 3 0 6 4 7
11~12 5 2 0 3 5 # df
----------------------------------------
week Mon Tues Wed Thur Fri
day 1 1 2 2 3
part
morning 11 9 8 9 6
afternoon 11 16 6 12 10
evening 8 2 6 7 12 # level = 0
----------------------------------------
day 1 2 3
part section
morning 1~2 7 3 4
3~4 13 14 2
afternoon 5~6 17 7 9
7~8 10 11 1
evening 9~10 3 10 7
11~12 7 3 5 # level = 1, axis = 1
----------------------------------------
17.5 去层次化索引
去层次化索引是想把层次化的变为非层次化的,二级将为一及,只有一层索引。还是以iris.csv数据为例,这个数据可以用行号和类型名分别为外层索引和内层索引先做成层次化索引的dataframe,然后去层次化。
import pandas as pd
import numpy as np
df = pd.read_csv("iris.csv", sep = ",", header = None, names = ["sepal_l","sepal_w", "petal_l", "petal_w", "class"])
print "-" * 40
print df[:10]
df.index.names = ["no."]
df["row_no."] = np.arange(len(df["sepal_l"]))
print "-" * 40
print df[:10], "# df"
df2 = df.set_index(["class","row_no."])
print "-" * 40
print df2[:10], "set_index"
print "-" * 40
print df2.index.levels[0], "# row index"
print "-" * 40
print df2.reset_index(level = 0)[:10], "reset level=0"
print "-" * 40
print df2.reset_index(level = 1)[:10], "reset level=1"
print "-" * 40
执行结果:
----------------------------------------
sepal_l sepal_w petal_l petal_w class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 4.6 3.4 1.4 0.3 Iris-setosa
7 5.0 3.4 1.5 0.2 Iris-setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
9 4.9 3.1 1.5 0.1 Iris-setosa
----------------------------------------
sepal_l sepal_w petal_l petal_w class row_no.
no.
0 5.1 3.5 1.4 0.2 Iris-setosa 0
1 4.9 3.0 1.4 0.2 Iris-setosa 1
2 4.7 3.2 1.3 0.2 Iris-setosa 2
3 4.6 3.1 1.5 0.2 Iris-setosa 3
4 5.0 3.6 1.4 0.2 Iris-setosa 4
5 5.4 3.9 1.7 0.4 Iris-setosa 5
6 4.6 3.4 1.4 0.3 Iris-setosa 6
7 5.0 3.4 1.5 0.2 Iris-setosa 7
8 4.4 2.9 1.4 0.2 Iris-setosa 8
9 4.9 3.1 1.5 0.1 Iris-setosa 9 # df
----------------------------------------
sepal_l sepal_w petal_l petal_w
class row_no.
Iris-setosa 0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
5 5.4 3.9 1.7 0.4
6 4.6 3.4 1.4 0.3
7 5.0 3.4 1.5 0.2
8 4.4 2.9 1.4 0.2
9 4.9 3.1 1.5 0.1 set_index
----------------------------------------
Index([u'Iris-setosa', u'Iris-versicolor', u'Iris-virginica'], dtype='object', name=u'class') # row index
----------------------------------------
class sepal_l sepal_w petal_l petal_w
row_no.
0 Iris-setosa 5.1 3.5 1.4 0.2
1 Iris-setosa 4.9 3.0 1.4 0.2
2 Iris-setosa 4.7 3.2 1.3 0.2
3 Iris-setosa 4.6 3.1 1.5 0.2
4 Iris-setosa 5.0 3.6 1.4 0.2
5 Iris-setosa 5.4 3.9 1.7 0.4
6 Iris-setosa 4.6 3.4 1.4 0.3
7 Iris-setosa 5.0 3.4 1.5 0.2
8 Iris-setosa 4.4 2.9 1.4 0.2
9 Iris-setosa 4.9 3.1 1.5 0.1 reset level=0
----------------------------------------
row_no. sepal_l sepal_w petal_l petal_w
class
Iris-setosa 0 5.1 3.5 1.4 0.2
Iris-setosa 1 4.9 3.0 1.4 0.2
Iris-setosa 2 4.7 3.2 1.3 0.2
Iris-setosa 3 4.6 3.1 1.5 0.2
Iris-setosa 4 5.0 3.6 1.4 0.2
Iris-setosa 5 5.4 3.9 1.7 0.4
Iris-setosa 6 4.6 3.4 1.4 0.3
Iris-setosa 7 5.0 3.4 1.5 0.2
Iris-setosa 8 4.4 2.9 1.4 0.2
Iris-setosa 9 4.9 3.1 1.5 0.1 reset level=1
----------------------------------------
语句df2 = df.set_index(["class","row_no."])将最后两列"class"和"row_no."作为两级索引,得到
----------------------------------------
sepal_l sepal_w petal_l petal_w
class row_no.
Iris-setosa 0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
5 5.4 3.9 1.7 0.4
6 4.6 3.4 1.4 0.3
7 5.0 3.4 1.5 0.2
8 4.4 2.9 1.4 0.2
9 4.9 3.1 1.5 0.1 set_index
----------------------------------------
这样的结果。语句print df2.reset_index(level = 0)是以内层索引为索引,去掉外层的索引,得到
----------------------------------------
class sepal_l sepal_w petal_l petal_w
row_no.
0 Iris-setosa 5.1 3.5 1.4 0.2
1 Iris-setosa 4.9 3.0 1.4 0.2
2 Iris-setosa 4.7 3.2 1.3 0.2
3 Iris-setosa 4.6 3.1 1.5 0.2
4 Iris-setosa 5.0 3.6 1.4 0.2
5 Iris-setosa 5.4 3.9 1.7 0.4
6 Iris-setosa 4.6 3.4 1.4 0.3
7 Iris-setosa 5.0 3.4 1.5 0.2
8 Iris-setosa 4.4 2.9 1.4 0.2
9 Iris-setosa 4.9 3.1 1.5 0.1 reset level=0
----------------------------------------
而语句df2.reset_index(level = 1)则是以外层做为索引,去掉内层索引,得到:
----------------------------------------
row_no. sepal_l sepal_w petal_l petal_w
class
Iris-setosa 0 5.1 3.5 1.4 0.2
Iris-setosa 1 4.9 3.0 1.4 0.2
Iris-setosa 2 4.7 3.2 1.3 0.2
Iris-setosa 3 4.6 3.1 1.5 0.2
Iris-setosa 4 5.0 3.6 1.4 0.2
Iris-setosa 5 5.4 3.9 1.7 0.4
Iris-setosa 6 4.6 3.4 1.4 0.3
Iris-setosa 7 5.0 3.4 1.5 0.2
Iris-setosa 8 4.4 2.9 1.4 0.2
Iris-setosa 9 4.9 3.1 1.5 0.1 reset level=1
----------------------------------------