41. Pandas数据可视化-基本步骤
在Python里常用matplotlib来绘制数据即数据的可视化输出。用pandas数据处理完毕后,一般调用plot绘制,调用show显示数据。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
v = np.random.normal(loc = 10, scale = 1, size = 200)
tx = pd.Series(v)
tx.index = pd.date_range('2018-12-01', periods = 200, freq = "d")
#print "tx", "-" * 20, "\n", tx
rm = tx.rolling(window = 5, center = False).std()
rm.plot()
tx.plot()
plt.show()
程序执行结果,如下图:
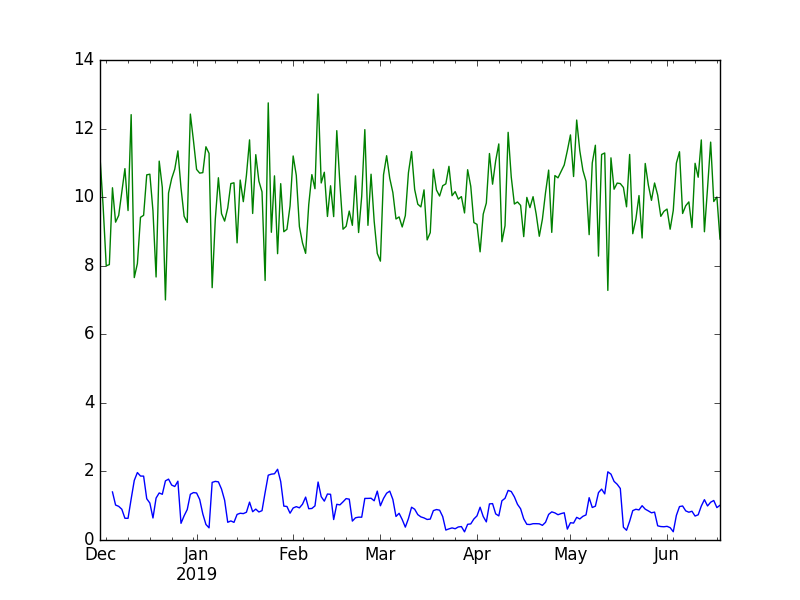
numpy模块下的random子模块里的nomal函数产生loc=10即概率分布的均值为10,scale = 1即标准差为1的数据共size =20个。而rm = tx.rolling(window = 5, center = False).std()语句的含义则是对这20个数据组建的时序序列数据进行窗口操作,窗口尺寸为5进行求标准差。而输出的图绿色是数据本身,蓝色的曲线则是求标准查std的结果。
由此可见在pandas里数据可视化一般经过以下几步:
- 通过import 语句引入matplotlib数据可视化模块里的pyplot,即语句
import matplotlib.pyplot as plt - 利用pandas产生或获取组织可视化的数据,例如程序里的rm和tx
- 对数据进行绘制,主要是使用了plot()函数,例如
rm.plot()和tx.plot() - 最后则是数据的显示输出,即
plt.show()。